Hybrid SQL–Synapse Data Mesh
This blueprint enables a domain-driven data mesh spanning on-prem SQL Server, Azure SQL, and Azure Synapse Analytics, with governed data products that publish read-optimized interfaces to consumers. It balances regulatory controls, performance, and cost using serverless/elastic compute, caching, and layered storage.
When to Use
- Regulated enterprises modernizing large SQL estates with incremental migration to Azure.
- Federated domains (Payments, Risk, Client 360) needing productized data with SLOs.
- Hybrid footprints where some sources remain on-prem for latency, data gravity, or compliance.
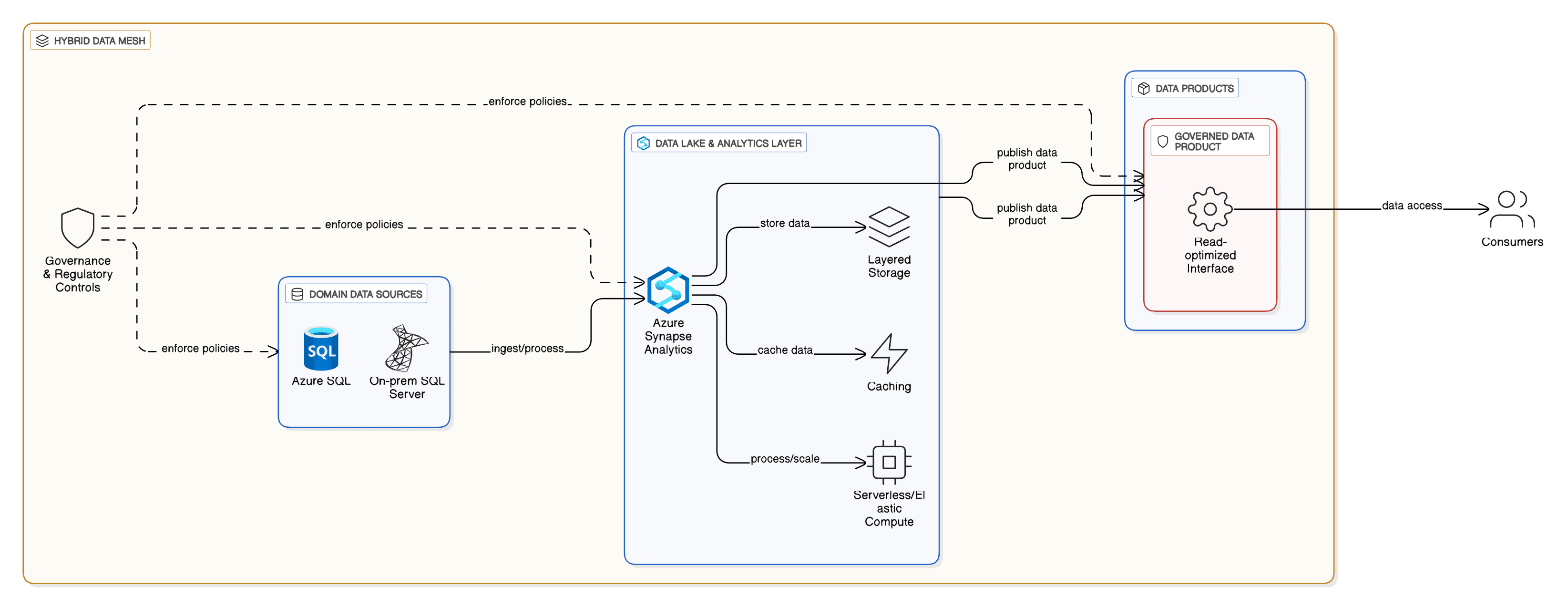
Logical Architecture
- Source Plane: On-Prem SQL Server, Oracle (optional), Azure SQL DB/MI, Event Hub/Kafka, SaaS APIs.
- Ingestion & Processing: ADF/Synapse Pipelines for batch; CDC via Azure DMS/SQL MI Link; streaming via Event Hub & Spark Structured Streaming.
- Storage Layers (ADLS Gen2): Raw (immutable), Curated (conformed), Product (domain contracts).
- Compute: Synapse serverless SQL for ad-hoc & virtualization; dedicated SQL pool for MPP warehouse; Spark for transformation/feature engineering.
- Serving: Azure SQL (read replicas), Synapse external tables/views, Power BI semantic models, APIs.
- Governance: Microsoft Purview (catalog, lineage, DQ), policy-as-code, Key Vault, private endpoints.
- Observability & FinOps: Log Analytics + Azure Monitor, SLO dashboards, workload isolation, cost guardrails.
Core Components
| Component | Purpose | Notes |
|---|---|---|
| Azure Data Factory / Synapse Pipelines | Batch ingestion & orchestration | IR for hybrid connectivity; trigger on CDC windows; parameterized pipelines. |
| SQL MI Link / DMS + CDC | Low-latency incremental replication | Use for near-real time ingestion from on-prem SQL to ADLS/Synapse. |
| ADLS Gen2 (Raw→Curated→Product) | Lake zoning & lifecycle | Immutable raw, curated conformed, product for domain contracts & SLAs. |
| Synapse (Serverless + Dedicated) | Virtualization + MPP warehousing | Serverless for cheap, elastic access; dedicated for heavy, repeatable workloads. |
| Azure SQL (read replicas) | Operational serving & APIs | Publish productized tables to consumer apps; optionally read replicas for scale. |
| Microsoft Purview | Catalog, lineage, DQ policies | Register domains, enforce PII tags, publish product contracts. |
| Entra ID + Private Endpoints | Zero-trust access control | MSI, RBAC, row-level & column-level security; VNet injection. |
Domain Data Products
Each domain publishes a contract (schema + semantics + SLOs) and exposes governed interfaces:Synapse views/external tables, Azure SQL tables, or Power BI semantic models.
- Schema Evolution: versioned contracts; backward-compatible changes via views.
- Quality: DQ rules (completeness, uniqueness, timeliness) validated in Curated before Product.
- Access: consumers onboarded via Purview collections + Entra security groups.
Security & Compliance
- Identity-based access (MSI) for pipelines and compute; secrets in Key Vault.
- Private endpoints for ADLS, Synapse, Azure SQL; no public exposure.
- Row-Level Security and Dynamic Masking on serving endpoints for least privilege.
- PII/PCI tagging in Purview; policy-driven sharing with audit trails.
Resilience & DR
- RPO: 15–30 mins (CDC to lake), RTO: 1–2 hrs (warm serverless + staged metadata).
- Geo-redundant storage (RA-GRS) for lake; recover metadata (Purview) via backup/export.
- Stateless pipelines; re-playable CDC offsets; checkpointed Spark streaming.
Performance & Cost (FinOps)
- Use serverless SQL for ad-hoc/interactive; auto-pause dedicated pools out of hours.
- Partitioning & file sizing: prefer 100–500 MB parquet files; pushdown predicates.
- Tiered storage & lifecycle policies; archive Curated after SLA windows.
Reference Diagram
Example: Serverless External Table on ADLS
-- In Synapse Serverless
CREATE EXTERNAL DATA SOURCE ds_adls
WITH ( TYPE = HADOOP, LOCATION = 'abfss://curated@<storageaccount>.dfs.core.windows.net' );
CREATE EXTERNAL FILE FORMAT parquet_format
WITH ( FORMAT_TYPE = PARQUET );
CREATE EXTERNAL TABLE product_payments
WITH (
LOCATION = '/payments/v1/',
DATA_SOURCE = ds_adls,
FILE_FORMAT = parquet_format
)
AS SELECT * FROM OPENROWSET(
BULK 'abfss://curated@<storageaccount>.dfs.core.windows.net/payments/v1/*.parquet',
FORMAT='PARQUET'
) AS src;Example: Contracted Consumer View
CREATE VIEW product_payments_v1 AS
SELECT
transaction_id,
merchant_id,
amount,
currency,
txn_ts AT TIME ZONE 'UTC' AS txn_utc,
customer_id -- masked / RLS applied downstream
FROM product_payments
WHERE txn_ts >= DATEADD(day, -90, SYSUTCDATETIME());Operational Runbook (Brief)
- Provision Purview, workspaces, storage (raw/curated/product), Key Vault, private endpoints.
- Stand up ingestion (CDC + batch) with parameterized pipelines per domain.
- Implement DQ checks → promote to Product only on pass.
- Expose product contracts (views/tables/models) and register in Purview.
- Set SLOs, alerts (latency, freshness, failure), and weekly cost/usage reviews.
Summary
This hybrid SQL–Synapse mesh lets domains publish governed, reliable data products with predictable SLOs while controlling cost via serverless access and tiered storage. It’s a pragmatic path for regulated institutions to modernize without a risky big-bang migration.