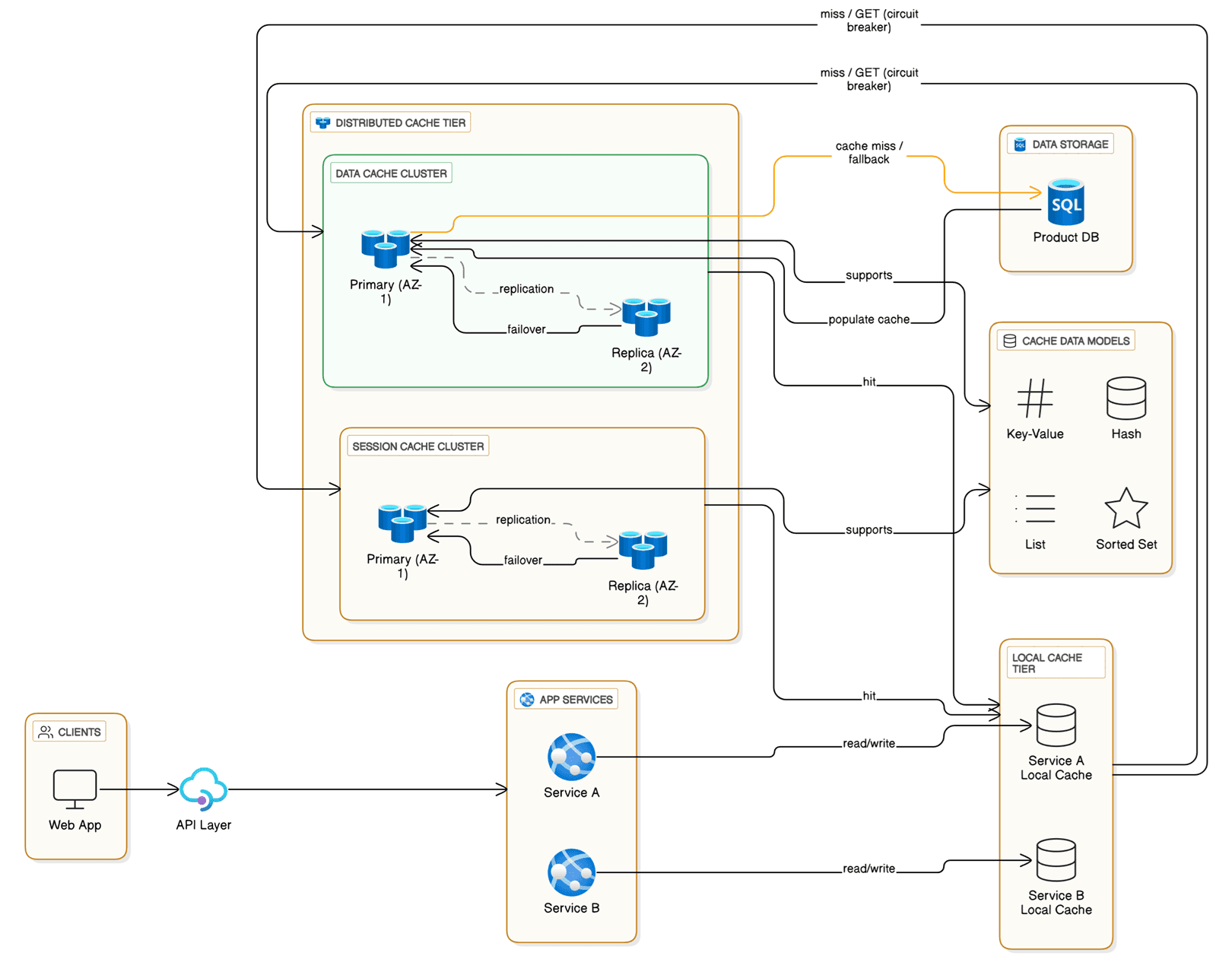
Reference Architecture Blueprint: Highly Resilient Caching
This architecture utilizes the Premium Tier or Azure Managed Redis (Enterprise / Flash) for maximum feature coverage and implements multiple layers of resilience for availability, durability, and disaster recovery.
1. High Availability (Intra-Region Resilience)
High availability ensures your cache remains operational during component failures within a single Azure region.
| Feature | Tier / Mechanism | Implementation Detail | Benefit |
|---|---|---|---|
| Replication | Standard, Premium, Enterprise | Each cache instance is deployed as a Primary/Replica pair (or multiple replicas in Premium/Enterprise). | Automatic failover to replica node if primary fails, maintaining continuity. |
| Zone Redundancy | Premium or Enterprise | Deploy nodes across multiple Azure Availability Zones within the same region. | Protects against data-center-level failures (power, cooling, network). |
| Clustering | Premium or Enterprise | Shard data across multiple primary nodes (shards). | Allows horizontal scaling and isolates impact of single node failure. |
2. Data Durability (Data-Loss Prevention)
Durability ensures data is not permanently lost in the event of a total cache failure.
| Feature | Tier | Implementation Detail | Benefit |
|---|---|---|---|
| Redis Persistence | Premium / Enterprise | Configure RDB or AOF persistence to save snapshots/logs to Azure Storage Account. | Rehydrates cache data after restart; prevents cold-cache latency and data loss. |
| Backup / Restore | All tiers | Use Import/Export to create backups to Page Blob and restore to a new cache instance. | Manual recovery or migration to new cache. |
3. Disaster Recovery (Cross-Region Resilience)
Disaster recovery ensures continuity if an entire Azure region becomes unavailable.
| Feature | Tier | Implementation Detail | Benefit |
|---|---|---|---|
| Geo-Replication | Premium (Passive) / Enterprise (Active) | Passive Geo-Replication asynchronously replicates to a secondary region; Active allows read/write access on both caches. | Provides hot or warm standby cache across regions for DR failover. |
| Client Connection Logic | Application Layer | Implement manual or automatic failover in client code to redirect traffic to secondary cache endpoint. | Enables seamless app-level switchover during regional outages. |
💡 Client & Application Resilience Best Practices
- Cache-Aside Pattern: The application manages the cache; on a miss, it retrieves data from the primary store (Azure SQL, Cosmos DB) and writes it back. Provides the final safety layer when Redis is unavailable.
- Connection Resilience: Implement Retry Pattern with Exponential Backoff (e.g., StackExchange.Redis for .NET) to handle transient issues or brief failovers.
- Circuit Breaker Pattern: Prevents the app from repeatedly hitting an unhealthy cache, avoids cascading failure, and falls back immediately to the primary data store.
- Monitoring & Alerting: Use Azure Monitor for metrics like Cache Hit Ratio, Load, Connected Clients. Alert on high latency, low hit ratio, or CPU spikes for proactive scaling.
Simplified Flow (Cache-Aside Pattern)
- Application attempts to read data from Azure Cache for Redis.
- Cache Hit: Data returned to application (fast path).
- Cache Miss / Failure:
- If circuit closed → retrieve from primary data store (Azure Cosmos DB / SQL), write back to cache, return data.
- If circuit open → skip cache, retrieve directly from primary store, handle fallback.
Summary
Combining intra-region high availability, data durability, and cross-region disaster recovery with strong client-side patterns ensures end-to-end cache resilience for mission-critical financial workloads on Azure.